Hauptinhalt
Frequently Asked Questions (FAQ)
Hier bekommen Sie Antworten auf die wichtigsten Fragen rund um's Forschungsdatenmanagement.
Einführung und Hintergründe
Was sind Forschungsdaten?
Was ist Forschungsdatenmanagement?
Warum ist Forschungsdatenmanagement wichtig für mich?
Was muss ich bei der Planung beachten?
Wie erstelle ich einen Datenmanagementplan?
Welche Anforderungen stellen Forschungsförderung, Verlage und Universität?
Forschungsdaten speichern und archivieren
Wie strukturiere ich meine Daten sinnvoll?
Welche Dateiformate sollten verwendet werden?
Wo speichere ich meine Daten im Arbeitsprozess?
Was sollte ich beim Backup meiner Daten beachten?
Wo archiviere ich meine Daten langfristig?
Forschungsdaten publizieren und teilen
Warum sollte ich meine Daten veröffentlichen?
Spricht etwas gegen eine Veröffentlichung?
Welche datenschutzrechtlichen Beschränkungen muss ich beachten?
Wer darf über die Weitergabe und Veröffentlichung von Daten entscheiden?
Besitze ich das Urheberrecht an meinen Daten?
Kann ich die Nutzung meiner Daten kontrollieren?
Welche Lizenz soll ich wählen?
Wie kann ich Daten veröffentlichen?
Wie finde ich ein passendes Repositorium?
Was muss ich bei der Einspeisung in ein Repositorium beachten?
Was sind Metadaten, Metadaten-Schemata, kontrollierte Vokabulare und Dokumentationen?
Was sind Persistent Identifier?
Forschungsdaten finden und nutzen
Wo finde ich Forschungsdaten?
Wie zitiere ich Forschungsdaten?
Einführung und Hintergründe
Was sind Forschungsdaten?
Als Forschungsdaten werden (digitale) Daten bezeichnet, die während eines Forschungsprozesses entstehen oder ein Ergebnis dessen sind. Da bei ihrer Gewinnung unterschiedlichste Methoden wie Messungen, Quellenforschungen oder Befragungen angewendet werden, sind Forschungsdaten stets fach- und projektspezifisch. Weiterführende Informationen zur Definition von Forschungsdaten finden Sie hier.
Was ist Forschungsdatenmanagement?
Forschungsdatenmanagement zielt auf den verantwortungsvollen, planvollen und nachhaltigen Umgang mit diesen Daten und nimmt dabei den gesamten Datenlebenszyklus (Data-Lifecycle, Abb. 1) in den Blick.
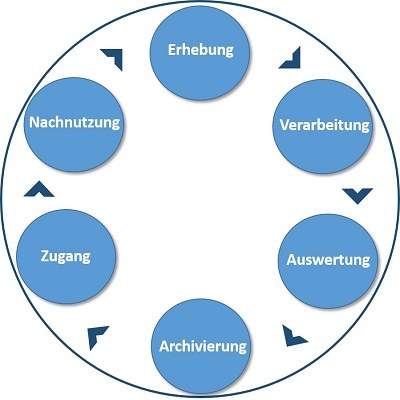
Abb. 1: Forschungsdatenlebenszyklus
Forschungsdatenmanagement beginnt demnach idealerweise bereits bei der Planung der Datenerhebung und befasst sich nicht nur mit der technischen Speicherung und Archivierung, sondern lenkt die Aufmerksamkeit auch darauf, die Daten auffindbar, zugreifbar, inhaltlich nachvollziehbar und somit langfristig nutzbar zu machen. Weiterführende Informationen zum Forschungsdatenmanagement finden Sie hier.
Warum ist Forschungsdatenmanagement wichtig für mich?
Folgende Gründe sprechen für ein systematisches Forschungsdatenmanagement und unterstreichen zugleich die Bedeutung für eine gute wissenschaftliche Praxis:
Forschungsförderung: Forschungsdatenmanagement, z.T. auch Data Sharing, wird vielfach von Forschungsförderungen gefordert, um die Validierung von Ergebnissen zu ermöglichen und Mehrfachförderung zu vermeiden. (Welche Anforderungen stellen Förderungen, Verlage und Universität?)
Nachnutzbarkeit: Gutes Forschungsdatenmanagement minimiert das Risiko von Datenverlusten und sichert die langfristige Nutzbarkeit von Daten, deren Gewinnung meist aufwendig und mit hohen Kosten verbunden ist, über die nach guter wissenschaftlicher Praxis geforderten 10 Jahre und darüber hinaus.
Reproduzierbarkeit: Werden experimentell gewonnene Forschungsdaten entsprechend gepflegt, ermöglicht das eine langfristige Reproduzierbarkeit von Ergebnissen.
Überprüfbarkeit: Die Dokumentation von Forschungsdaten und ihrer Entstehung macht Ergebnisse auch langfristig überprüfbar.
Zitierfähigkeit: Datenpublikationen sind als eigenständige Publikationen voll zitierfähig und erhöhen so die Sichtbarkeit der eigenen Forschung.
Die folgende Abbildung zeigt außerdem die Ziele, die in verschiedenen Kontexten mit dem Forschungsdatenmanagement verfolgt werden können:
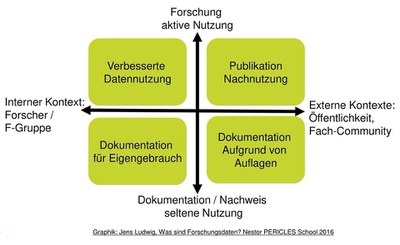
Abb. 2: Ziele, die mit FDM verfolgt werden können
Was muss ich bei der Planung beachten?
Idealerweise beginnt Forschungsdatenmanagement nicht erst, nachdem die Daten erhoben wurden. Vielmehr sollten bereits vor der Erhebung Überlegungen angestellt werden, wie mit den Daten umgegangen werden soll. Zur Orientierung kann der Datenlebenszyklus dienen.
Einen Überblick, was bei der Durchführung des Forschungsdatenmanagements berücksichtigt werden sollte, gibt folgende Anleitung der Universität Kassel:
-
Legen Sie fest, wer bei Ihnen für die Einrichtung und Kontrolle des Forschungsdatenmanagements verantwortlich ist.
-
Überprüfen Sie, ob es für Ihre Fachdisziplin spezifische institutionelle oder allgemeine Vorgaben oder Vorschläge zum Forschungsdatenmanagement gibt.
-
Stellen Sie bei jedem Forschungsvorhaben möglichst früh fest, welchen Verpflichtungen zur Aufbewahrung und Veröffentlichung von Forschungsdaten Sie unterliegen. (Welche Anforderungen stellen Förderungen, Verlage und Universität?)
-
Stellen Sie fest, welche Forschungsdaten bei dem Forschungsvorhaben erhoben werden.
-
Überlegen Sie, welche der Forschungsdaten veröffentlicht und anderen zur Nachnutzung zur Verfügung gestellt werden sollen.
-
Überlegen Sie, wie Sie Forschungsdaten aufbewahren und archivieren wollen. (Forschungsdaten speichern und archivieren)
-
Prüfen Sie, welche Aufbewahrungs- und Archivierungsmöglichkeiten Ihnen zur Verfügung stehen. Könnten Sie ein allgemeines oder fachspezifisches Datenrepositorium nutzen? (Wie finde ich ein passendes Repositorium?)
-
Klären Sie die rechtlichen Fragen zur Aufbewahrung und Weitergabe von Forschungsdaten. Dies kann u.a. Datenschutz- und Urheberrecht betreffen.
-
Erstellen Sie einen Datenmanagementplan. Dieser dokumentiert Ihre Entscheidungen und dient Ihnen als Nachweis der Durchführung. (Wie erstelle ich einen Datenmanagementplan?)
Aktualisieren Sie den Datenmanagementplan im Verlauf des Forschungsvorhabens.
Wie erstelle ich einen Datenmanagementplan?
In einem Datenmanagementplan wird der Umgang mit Forschungsdaten von der Planung bis zum Abschluss eines Forschungsvorhabens dokumentiert. Er stellt jedoch ein „lebendiges Dokument” dar, das an Änderungen, neue Erkenntnisse oder Probleme angepasst werden kann und muss.
Bei der Erstellung von Datenmanagementplänen helfen Ihnen folgende Tools:
- RDMO
Der Research Data Management Organiser (RDMO) wurde vom Leibniz-Institut für Astrophysik Potsdam und der Fachhochschule Potsdam entwickelt. Das von der DFG geförderte Projekt befindet sich momentan in der zweiten Projektphase. RDMO ermöglicht nicht nur die Erstellung eines Datenmanagementplans gemäß den Vorgaben verschiedener Forschungsförderungen, sondern unterstützt Forschende auch bei der Planung, Umsetzung und Verwaltung aller Aufgaben des Forschungsdatenmanagements. Die UMR bietet den RDMO an: www.rdmo.uni-marburg.de -
DMPonline
DMPonline wird vom britischen Digital Curation Centre (DCC) betrieben. Die Anwendung ist vor allem auf die Situation im Vereinigten Königreich zugeschnitten, kann aber auch für Horizon 2020-Projekte genutzt werden. Für den deutschsprachigen Raum stellt die Humboldt-Universität zu Berlin eine Handreichung zur Benutzung von DMPonline für Horizon 2020 zur Verfügung. -
DMPTool
DMPTool wird von der California Digital Library betrieben. Die Webseite bietet auch Beispiele für Datenmanagementpläne. Das Tool orientiert sich an der Förderlandschaft in den USA und ist daher nur eingeschränkt für deutsche bzw. europäische Projekte nutzbar. -
ARGOS
ARGOS ist ein von OpenAIRE entwickeltes, europäisches Online-Tool zur Erstellung von Datenmanagementplänen, das auf der Open Source-Software OpenDMP basiert. Die Anmeldung ist sehr offen gestaltet, da man sich direkt mit seiner ORCiD ID, seinem Google Account oder auch per Facebook- oder Twitter-Account einloggen kann. Datenmanagementpläne, die mit ARGOS erstellt werden, sind außerdem international anschlussfähig, da diese direkt im DMP-Metadatenstandard der Research Data Alliance (RDA) vorliegen. -
Die folgenden Checklisten, Muster, Templates und Wizards geben weitere Hilfestellungen bei der Erstellung von Datenmanagementplänen:
Checklisten:
- Checkliste des Digital Curation Center der Universität Edinburgh
- Fragenkatalog „Twenty Questions for Research Data Management” des Oxforder Zoologen David Shotton
-
Muster & Templates:
-
Wizards:
- Hilfreich sind außerdem folgende Beispiele für Datenmanagementpläne:
-
Einen guten Einstieg in das Thema „Datenmanagementpläne” bietet auch das kurze Video-Tutorial der HU-Berlin.
Welche Anforderungen stellen Forschungsförderung, Verlage und Universität?
- Deutsche Forschungsgemeinschaft (DFG)
Die DFG trifft in ihren am 1. August 2019 in Kraft getretenen ‚Leitlinien zur Sicherung guter wissenschaftlicher Praxis’ grundlegende Festlegungen zum Umgang mit Forschungsdaten und verlangt u. a., dass „Forschungsdaten […] in der Regel für einen Zeitraum von zehn Jahren zugänglich und nachvollziehbar […] aufbewahrt” werden.
Ferner heißt es in der Leitlinie:
„Aus Gründen der Nachvollziehbarkeit, Anschlussfähigkeit der Forschung und Nachnutzbarkeit hinterlegen Wissenschaftlerinnen und Wissenschaftler, wann immer möglich, die der Publikation zugrunde liegenden Forschungsdaten […] zugänglich in anerkannten Archiven und Repositorien.”
Die 2015 verabschiedeten ‚Leitlinien für den Umgang mit Forschungsdaten’ enthalten weitere Empfehlungen für die Bereitstellung von Daten, aber auch die datenbezogene Projektplanung. Hierzu wird u. a. ausgeführt:
„Bereits in die Planung eines Projekts sollten Überlegungen einfließen, ob und welche der aus einem Vorhaben resultierenden Forschungsdaten für andere Forschungskontexte relevant sein können und in welcher Weise diese Forschungsdaten anderen Wissenschaftlerinnen und Wissenschaftlern zur Nachnutzung zur Verfügung gestellt werden können. In einem Antrag sollten die Antragstellenden daher ausführen, welche Forschungsdaten im Verlauf eines wissenschaftlichen Forschungsvorhabens entstehen, erzeugt oder ausgewertet werden. Dabei sollten fachspezifisch angemessene Konzepte und Überlegungen für die Qualitätssicherung, für den Umgang mit und die langfristige Sicherung der Forschungsdaten zugrunde gelegt werden.”
- Europäische Kommission (EC)
Die Kommission realisiert im Rahmen des Programms Horizon 2020 ein Pilotprojekt, das als Open Research Data Pilot bezeichnet wird und darauf abzielt, den Zugang zu und die Weiterverwendung von Forschungsdaten aus Horizon 2020-Projekten zu verbessern. Der Open Research Data Pilot folgt dabei dem Grundsatz „so offen wie möglich, so geschlossen wie nötig”.
Während in den Arbeitsprogrammen 2014-2016 nur ausgewählte Bereiche von Horizon 2020 in das Projekt einbezogen wurden, erstreckt sich der Pilot in der überarbeiteten Version des Arbeitsprogramms 2017 nun auf alle Themenbereiche.
Es gelten folgende Regelungen:
Erstellung eines Datenmanagementplans entsprechend der Vorlage. Einreichung innerhalb der ersten sechs Monate, Aktualisierung bei relevanten Änderungen bzw. mindestens zum Zeitpunkt der Zwischen- und Abschlussevaluation des Projekts.
Datenablage: Forschungsdaten müssen so bald wie möglich (gilt für Daten, die einer Projektpublikation zugrunde liegen) bzw. entsprechend dem Datenmanagementplan (gilt für andere Daten) in einem geeigneten, möglichst institutionellen, projekt- oder fachspezifischen Repositorium hinterlegt werden.
Veröffentlichung: Sofern möglich, sollen die Daten ohne Nutzungsbeschränkung unter einer offenen Lizenz (bevorzugt CC-BY oder CC-0) einschließlich der benötigten Kontextinformationen und -tools veröffentlicht werden.
Eine teilweise bzw. vollständige Befreiung von den Auflagen aufgrund berechtigter Gründe ist jedoch möglich. (Spricht etwas gegen eine Veröffentlichung?)
Weiterführende Informationen finden Sie hier:
Guidelines on FAIR Data Management in Horizon 2020
Guidelines on Open Access to Scientific Publications and Research Data in Horizon 2020
Horizon 2020 Online Manual: Open Access and Data Management
Horizon 2020: Annotated Model Grant Agreement (AGA)
OpenAIRE Research Data Management Briefing Paper
- Verlage
|
Da auch Verlage in zunehmendem Maße die Bereitstellung derjenigen Forschungsdaten fordern, die einer Publikation zugrunde liegen, sollten Sie dahingehende Vorgaben vor einer Veröffentlichung prüfen. Im Folgenden haben wir einige Beispiele für Sie zusammengestellt: |
Public Library of Science (PLoS): Data Availability / Materials and Software Sharing
Nature Publishing Group: Availability of Data, Materials, Code and Protocols
Science: Data and Materials Availability / Preparing Supplementary Materials
BioMed Central: Availability of Data and Material
Elsevier: Research Data Policy / Text and Data Mining Policy
Forschungsdaten speichern und archivieren
Wie strukturiere ich meine Daten sinnvoll?
Da im Arbeitsprozess häufig nicht nur zahlreiche Datensätze, sondern durch verschiedene Modifizierungsstufen auch jeweilige Versionen entstehen, ist es empfehlenswert, einheitliche Festlegungen zur Datei-Benennung und Versionierung zu treffen. Dies erhöht die Arbeitseffektivität und fördert kollaborative Arbeitsprozesse. Darüber hinaus wird die langfristige Nachvollziehbarkeit sowie eine Nachnutzbarkeit von Daten ermöglicht.
Weiterhin kann es sinnvoll sein, getrennte Ordnerstrukturen für Rohdaten, Analysedaten und Datenauswertungen sowie weitere Projektmaterialien zu definieren. Weitere Informationen zur Datenorganisation bietet Jensen 2012, S.40-42.
Informationen zur "Datei- und Ordnerorganisation" bietet dieser kurze Vortrag von Christian Krippes.
In den verschiedenen Modifikationsstadien (z.B. Originaldaten, bereinigte Daten, analysefähige Daten) sollten schreibgeschützte Versionen erstellt werden. Weitere Bearbeitungen sollten nur in Kopien dieser Master-Dateien erfolgen.
Aufgrund der jeweiligen Besonderheiten der Forschungsbereiche, aber auch der Daten selbst können Namenskonventionen ganz unterschiedlich ausgestaltet sein. Sie sollten jedoch stets die Art der Datendateien (Originaldaten, bereinigte Dateien, Analysedateien) und auch die jeweilige Dateiform (Arbeitsdatei, Ergebnisdatei etc.) berücksichtigen.
Das Speicherdatum sollte in der Dateibenennung enthalten sein, dem YYYYMMDD-Format folgen und am Beginn oder am Ende des Dateinamens stehen, um die Sortierung zu erleichtern. Verzichten Sie auf Sonderzeichen und Umlaute sowie auf Leerzeichen und verwenden Sie stattdessen Unterstriche. Die Bezeichnungen sollten stets einheitlich, eindeutig und aussagekräftig sein.
Beispiele für Dateibenennungen sind etwa (s. auch HU Berlin: Dateien strukturieren):
- [Sediment]_[Probe]_[Instrument]_[YYYYMMDD].dat
- [Experiment]_[Reagens]_[Instrument]_[YYYYMMDD].csv
- [Experiment]_[Versuchsaufbau]_[Versuchsperson]_[YYYYMMDD].sav
- [Beobachtung]_[Ort]_[YYYYMMDD].mp4
- [Interviewpartner]_[Interviewer]_[YYYYMMDD].mp3
Die hier aufgeführten Dateibenennungen folgen dem sogenannten Schreibstil "Pothole Case" (auch "Snake Case"). Zu erkennen ist dies an den Unterstrichen, die als Trennstriche verwendet werden. Für gewöhnlich werden die Buchstaben nach jedem Unterstrich klein geschrieben, es ist aber auch möglich, alle Anfangsbuchstaben nach den Unterstrichen groß zu schreiben.
Neben dem Pothole Case gibt es auch noch zahlreiche andere Schreibstile zur Benennung von Dateien. Einer der gängigsten ist der Camel Case. Folgendes Beispiel zeigt eine Dateibenennung im Camel Case: "SedimentProbeInstrumentYYYYMMDD.dat". Jedes Wort beginnt mit einem Großbuchstaben, eine Abtrennung über einen Unterstrich, wie beim Pothole Case, oder ein anderes Sonderzeichen gibt es nicht. Nachteil dieser Benennungskonvention ist beispielsweise die Angabe von Versionen (s. nächsten Absatz). Eine Version 1.0.0 würde im Pothole Case als 1_0_0 erkennbar sein, im Camel Case als 100. Egal, für welchen Stil Sie sich entscheiden, sollten Sie darauf achten, während der gesamten Projektlaufzeit den gleichen zu verwenden.
Veränderungen der Daten können durch die Angabe der Version im Dateinamen kenntlich gemacht werden. Ein bekanntes Konzept der Versionierung, das auf dem DDI-Standard (Data Documentation Initiative) basiert, lautet: Major.Minor.Revision.
Ausgehend von der Version „1.0.0” werden dabei geändert:
- die erste Stelle, wenn Fälle, Variablen, Wellen oder Sample hinzugefügt oder gelöscht wurden
- die zweite Stelle, wenn Daten korrigiert werden, sodass die Analyse beeinflusst wird
- die dritte Stelle, wenn einfache Überarbeitungen ohne Bedeutungsrelevanz vorgenommen werden
Versionierung kann auch durch entsprechende Software unterstützt werden (z. B. Git).
Welche Dateiformate sollten verwendet werden?
Um Daten langfristig aufbewahren und nachhaltig nutzen zu können, ist die Wahl eines geeigneten Dateiformats von besonderer Bedeutung. Grundsätzlich sollte darauf geachtet werden, dass Dateien bzw. Formate nicht verschlüsselt, komprimiert, proprietär oder patentiert sind. Bevorzugen Sie dementsprechend offene, dokumentierte Standards.
Empfehlungen, welche Dateiformate bevorzugt werden sollten, finden Sie u. a. bei RADAR, der HU Berlin, dem UK Data Service oder der Library of Congress.
Eine Orientierung bietet auch die nachfolgende Tabelle:
| Datentyp | Empfohlene Formate | weniger geeignete bzw. ungeeignete Formate |
|---|---|---|
| Audio | .wav / .flac | .mp3 |
| Computer-aided Design (CAD) | .dwg / .dxf / .x3d / .x3db / .x3dv | - |
| Datenbanken | .sql / .xml | .accdb / .mdb |
| Rastergrafiken & Bilder | .tif (unkomprimiert) / .jp2 / .jpg2 / .png | .gif / .jpeg / .jpg / .psd |
| Statistische Daten | .por | .sav (IBM®SPSS) |
| Tabellen | .csv / .tsv / .tab | .xls / .xlsx / .xlx |
| Texte | .odf / .rtf / .txt / PDF/A | .docx / .doc / PDF |
| Vektorgrafiken | .svg / .svgz | .cdr |
| Video | .mov / .wmv |
Wo speichere ich meine Daten im Arbeitsprozess?
Die regelmäßige Sicherung der Daten im Arbeitsprozess ist angesichts möglicher technischer und menschlicher Fehler sehr wichtig. Sie obliegt der Verantwortung der Forschenden, die darin von der Infrastruktur der Universität unterstützt werden. Das HRZ bietet dazu folgende Lösungen:
- Cloudspeicher: Hessenbox
Das HRZ der Uni Marburg stellt allen Beschäftigten und Studierenden einen kostenlosen Cloud-Speicher von 30 GB zur Verfügung. So können Daten einfach synchronisiert, ausgetauscht und beispielsweise auch Externen zur Verfügung gestellt werden. Die Hessenbox ermöglicht es Ihnen außerdem, Dokumente kollaborativ zu bearbeiten.
- Netzlaufwerke: Fileservice
Für die Sicherung aller Daten und Dokumente, die während des Forschungsprozesses aufkommen, bietet das HRZ bedarfsgerechte Speicherangebote. Neben den üblichen (Gruppen) Netzlaufwerken (H:, K: und L:) kann weiterer Speicherplatz angemietet werden. Die Daten werden regelmäßig gesichert. Die Netzlaufwerke lassen sich außerdem komfortabel in die Dateiverwaltung Ihres Arbeitsplatzrechners einbinden.
- Datensicherung: Backup-Service
Für lokal gespeicherte Daten (i. d. R. Laufwerk D: oder E:) oder Daten auf eigenen Fileservern in den Fachbereichen und Einrichtungen gibt es außerdem noch den Backup-Service. Bei diesem Verfahren werden die Daten regelmäßig (einmal in der Nacht) werktäglich (Montag – Freitag) auf Magnetbänder gesichert. Es werden nur die Daten gesichert, die seit der letzten Sicherung neu hinzugekommen sind oder sich geändert haben. Das Verfahren der Bandsicherung eignet sich auch für die Langzeitdatenaufbewahrung (Archive-Service).
Im Falle größeren Speicherplatzbedarfs können Sie zusätzlich zu dem Standardangebot Fileservice für persönliche oder projektbezogene Daten mieten, siehe "Zusatzangebote - Speicherplatz für Fachbereiche und Einrichtungen" unter Fileservice.
Was sollte ich beim Backup meiner Daten beachten?
Gutes Forschungsdatenmanagement zeichnet sich auch dadurch aus, dass Sie als Forschende auf einen möglichen Datenverlust bestmöglichst vorbereitet sind. Deshalb sollten Sie bereits zu Beginn Ihres Forschungsprojektes einen Backup-Plan erstellen, der im Bestfall auch regelmäßige Backup-Routinen enthalten sollte. Folgende Fragen sollten in einem Backup-Plan beantwortet werden:
- Welches Backup-Tool verwenden Sie?
- Von welchen Daten soll ein Backup erstellt werden?
- Wo sollen die Backups der Daten gespeichert werden?
- Wie oft sollen Backups der Daten vorgenommen werden?
Außerdem sollten Sie die sogenannte 3-2-1-Backup-Regel beachten (s. Abb. 3). Diese besagt, dass Sie von Ihren Daten immer mindestens 3 Kopien auf 2 unterschiedlichen Datenträgern (also beispielsweise einem USB-Stick und einer externen Festplatte) sowie 1 an einem dezentralen Speicherort (also beispielsweise der Hessenbox) vorhalten sollten. Wichtig ist, dass alle 3 Kopien immer auf dem aktuellen Stand der Originaldatei vorliegen, weshalb sich automatisierte Backup-Routinen am besten eignen. Eine Anleitung, wie Sie mit der Windows-Aufgabenplanung automatisierte Backup-Routinen erstellen können, finden Sie hier.
Abb. 3: 3-2-1 Backup-Regel
Sollten Sie mit personenbezogenen Daten oder anderen rechtlich sensiblen Daten arbeiten, bedenken Sie, dass zumindest das Backup an einem dezentralen Speicher- bzw. Aufbewahrungsort eine Sicherung auf einem Band mit sich bringt, auf die Sie ohne Weiteres keinen Einfluss mehr haben. Sollten Sie Ihre Daten beispielsweise in der Hessenbox sichern, dann werden Backups in den Einrichtungen des HRZ angelegt. Einem möglichen Wunsch auf Löschung der Daten können Sie dann nur noch schwierig nachkommen. Bitte verschlüsseln Sie solche rechtlich sensiblen Daten also vor der Speicherung an einem dezentralen Speicherort. Dafür können Sie entweder einen Zip-Ordner erstellen, den Sie mit einem Passwort versehen, oder Sie nutzen die Tools VeraCrypt oder Rohos MiniDrive. (Welche datenschutzrechtlichen Beschränkungen muss ich beachten?)
Wo archiviere ich meine Daten langfristig?
Gemäß den Grundsätzen guter wissenschaftlicher Praxis sollen Forschungsdaten über einen Zeitraum von mindestens 10 Jahren aufbewahrt werden. Hierfür stehen fachspezifische und fachübergreifende Repositorien zur Verfügung. (Wie finde ich ein passendes Repositorium?)
Dabei ist der Upload in ein Repositorium nicht gleichbedeutend mit einer Veröffentlichung der Daten. Beispielsweise kann ein Zeitraum festgelegt werden, in dem ein Datenpaket noch nicht zugänglich, die Metadaten indes bereits sichtbar sind. Solche Embargofristen können durch einen Kurator verlängert werden. Weiterführende Informationen zum Thema "Embargo" finden sie hier. Im Falle einer Veröffentlichung können Zugriffs- und Bearbeitungsrechte außerdem in Verträgen oder durch Lizenzen geregelt werden. (Kann ich die Nutzung meiner Daten kontrollieren? / Welche Lizenz soll ich wählen?)
Beachten Sie bitte auch die jeweiligen Vorgaben von Forschungsförderungen und Verlagen sowie datenschutzrechtliche Bestimmungen. (Wer darf über die Weitergabe und Veröffentlichung von Daten entscheiden? / Welche datenschutzrechtlichen Beschränkungen muss ich beachten?)
Forschungsdaten publizieren und teilen
Warum sollte ich meine Daten veröffentlichen?
Die Publikation von Forschungsdaten bietet viele Vorteile, nicht nur für einzelne Wissenschaftlerinnen und Wissenschaftler, sondern auch für die scientific community und den gesamten Wissenschaftsbetrieb.
Zum einen sind publizierte Datensätze als eigenständige wissenschaftliche Leistung zitierfähig und erhöhen die Sichtbarkeit der eigenen Forschung. Denn wie Untersuchungen zeigen, werden Veröffentlichungen häufiger zitiert, wenn auch die jeweils zugrunde liegenden Daten publiziert wurden. (s. Piwowar & Vision 2013)
Zum anderen ermöglicht Data Sharing die Nachnutzung bereits vorhandener Daten. Auf diese Weise können neuartige Fragestellungen untersucht, zugleich aber auch Doppelarbeit vermieden und Kosten reduziert werden.
Spricht etwas gegen eine Veröffentlichung?
Es gibt Konstellationen, unter denen eine Veröffentlichung der Daten nicht oder nur unter bestimmten Bedingungen erfolgen sollte. Wichtigste Voraussetzung für eine Veröffentlichung ist, dass Sie über das Recht hierzu verfügen. (Wer darf über die Weitergabe und Veröffentlichung von Daten entscheiden? / Besitze ich das Urheberrecht an meinen Daten?)
Zum anderen kann es sich um vertrauliche personenbezogene Daten handeln, die nur nach Anonymisierung oder mit Einverständnis der Betroffenen veröffentlicht werden dürfen. (Welche datenschutzrechtlichen Beschränkungen muss ich beachten?)
Sollten Sie bei einem Verlag veröffentlichen wollen, achten Sie außerdem darauf, den Verlag mit Bedacht zu wählen und nicht auf sogenannte Raubverlage hereinzufallen. Dieser kurze Vortrag von Werner Dees bietet einen kurzen Überblick, woran Sie Raubverlage erkennen können.
Welche datenschutzrechtlichen Beschränkungen muss ich beachten?
Unter personenbezogenen Daten versteht man "alle Informationen, die sich auf eine identifizierte oder identifizierbare natürliche Person (betroffene Person) beziehen; als identifizierbar wird eine natürliche Person angesehen, die direkt oder indirekt, insbesondere mittels Zuordnung zu einer Kennung wie einem Namen, zu einer Kennnummer, zu Standortdaten, zu einer Online-Kennung oder zu einem oder mehreren besonderen Merkmalen, die Ausdruck der physischen, physiologischen, genetischen, psychischen, wirtschaftlichen, kulturellen oder sozialen Identität dieser Person sind, identifiziert werden kann" (§ 46 Abs. 1 BDSG). Sie unterliegen in ihrer Erhebung, Nutzung und Weitergabe strengen Vorgaben. Für die Archivierung, Bereitstellung und Veröffentlichung sollten Informationen, die einer bestimmten oder bestimmbaren Person zugeordnet werden können, aus den Forschungsdaten entfernt werden. Abhängig von den Daten eignen sich hier verschiedene Wege der Anonymisierung.
Sollen personenbezogene Daten verarbeitet werden, muss in der Regel die Einwilligung der betroffenen Person eingeholt werden. Hierbei muss u.a. der Zweck klar definiert werden und die betroffene Person die Folgen abschätzen können.
Darüber hinaus können Forschungsdaten wie etwa Unternehmensdaten vertrauliche Informationen enthalten (Know-How-Schutz) oder Vertraulichkeits- und Geheimhaltungsvereinbarungen getroffen worden sein, die eine Veröffentlichung ausschließen.
Wer darf über die Weitergabe und Veröffentlichung von Daten entscheiden?
Mögliche Besitzende oder Mitbesitzende der Rechte an den Daten sind die Forschenden, die Arbeitgebenden, die Auftraggebenden, Forschungsförderung und/oder (privatwirtschaftliche) Vertragspartner und -partnerinnen. Wer über die Weitergabe oder Veröffentlichung von Forschungsdaten mitentscheiden darf oder gefragt werden muss, bestimmt sich über die Vertragsverhältnisse. Üblicherweise sind Ergebnisse weisungsgebundener Forschung Eigentum der Arbeit- bzw. Geldgebenden. Anders verhält es sich bei eigener Forschung, über deren Daten Forschende selbst bestimmen dürfen.
Besitze ich das Urheberrecht an meinen Daten?
Forschungsobjekte und vereinzelt auch Forschungsdaten können als Werk im Sinne des Urhebergesetzes geschützt sein. Das können sein: Sprachwerke, Computerprogramme, Musikwerke, Pantomimische Werke einschließlich Werke der Tanzkunst, Werke der bildenden Künste einschließlich der Werke der Baukunst und der angewandten Kunst, Lichtbildwerke, Filmwerke und Darstellungen wissenschaftlicher und technischer Art.
In der Regel fehlt Forschungsdaten aber die notwendige Schöpfungshöhe und sie sind keine Werke. In Betracht kommt aber, dass bestimmte Arten von Forschungsdaten unter ein Leistungsschutzrecht fallen, zum Beispiel Lichtbilder, Laufbilder oder Tonträger.
Oft sind die Forschungsdaten eines Forschungsvorhabens aber als Teil eines Datenbankwerks urheberrechtlich geschützt oder fallen unter das Leistungsschutzrecht für Datenbanken.
Forschungsdaten, die nicht unter ein Schutzrecht fallen, können in der Regel von jedermann ohne eine Genehmigung oder Zahlungsverpflichtung zu jedem beliebigen Zweck verwendet werden.
Kann ich die Nutzung meiner Daten kontrollieren?
Sofern Sie ein Urheberecht oder Leistungsschutzrecht über Forschungsdaten besitzen, können Sie verschiedene Aspekte der Nutzung über entsprechende Verträge regulieren, wie etwa Art und Weise der Nutzung, Nutzergruppen und –zeitraum, Zweck etc. Da vertragliche Einzelfallregelungen praktisch sehr aufwendig wären, existieren verschiedene Lösungen der standardisierten Regelungen von Nutzungsrechten. So bietet beispielsweise das Leibniz-Zentrum für Psychologische Information und Dokumentation (ZPID) Standardverträge für die Nutzung der psychologischen Daten und GESIS regelt über Nutzungsverträge die Zugangsbeschränkungen für besonders sensible sozialwissenschaftliche Daten. Wenn Ihre Daten keiner spezifischen Zugriffs- oder Nutzungsbeschränkung unterliegen sollen, bietet sich die Verwendung standardisierter Lizenzen wie Creative Commons oder Open Data Commons an. (Welche Lizenz soll ich wählen?)
Welche Lizenz soll ich wählen?
Die Veröffentlichung von Daten unter einer bestimmten Lizenz erlaubt eine detaillierte Festlegung der zulässigen Form ihrer Nutzung. Sie schaffen Rechtssicherheit sowohl auf Seiten der bereitstellenden als auch der nutzenden Person. Auch bei dem Verzicht auf jegliche Beschränkungen ist es daher wichtig, diesen zu formulieren.
Wenngleich Daten selbst in der Regel nicht dem Urheberrecht unterliegen, spricht dennoch einiges dafür, sie als potentiell schützenswert zu behandeln, nicht zuletzt um den eigenen Vorstellungen der Weiternutzung Ausdruck zu verleihen. Hierfür bieten sich verschiedene Lizenzmodelle an. Das verbreitetste unter ihnen ist Creative Commons (CC). CC-Lizenzen sind unabhängig vom lizenzierten Inhalt und decken Urheberrechte, Leistungsschutzrechte und in der aktuellen Version – sofern existent – auch Datenbankherstellerrecht ab.
Speziell für die Veröffentlichung von Daten ist das Lizenz-Paket ‚Open Data Commons' der Open Knowledge Foundation konzipiert worden. Neben der bedingungslosen Lizenz (Open Data Commons Public Domain Dedication and License (PDDL)) bietet es drei weitere Modelle:
- Open Data Commons Attribution License (ODC BY v1.0): Bedingung der Namensnennung
- Open Data Commons Open Database License (ODbL v1.0): Weitergabe unter gleichen Bedingungen
- Database Contents License (DbCL v1.0): Weitergabe unter gleichen Bedingungen auch für Datenbankinhalte
Unabhängig von Ihrer rechtlichen Verbindlichkeit erfüllt die Lizenz CC-BY die Idee von Open Access und Open Science sicherlich am ehesten, wogegen die ‚Weitergabe unter gleichen Bedingungen' zu Kompatibilitätsproblemen mit anderen Lizenzen, das Verbot von Bearbeitung zu Einschränkungen bei Nutzung durch z.B. Data-Mining oder auch zu Problemen bei der Langzeitarchivierung führen kann. Das Verbot kommerzieller Nutzung erschwert die Verwendung in kommerziellen Datenbanken und reduziert damit potentiell die Sichtbarkeit Ihrer Forschung.
Welche Lizenz Sie auch wählen – Sie sollten eine bewusste und informierte Entscheidung treffen. Eine ausführlichere Auseinandersetzung mit der Thematik finden Sie bei Wiebe & Guibault 2013. Dieser Vortrag von Frank Waldschmidt-Dietz bietet ebenfalls noch einmal einen kurzen Überblick über Creative Commons Lizenzen und Lizenzierung im Allgemeinen. Welche Vorteile freie, Open Access-fördernde Lizenzen für die Bildung bringen, zeigt ebenfalls Frank Waldschmidt-Dietz in einem Video zu Open Educational Resources, kurz OER.
Unabhängig von den Nutzungsbedingungen gelten selbstverständlich die Regeln guter wissenschaftlicher Praxis, die eine Angabe der Quelle verwendeter Daten fordern.
Wie kann ich Daten veröffentlichen?
Um Daten zu veröffentlichen, stehen sowohl fachübergreifende als auch fachspezifische Repositorien zur Verfügung. Letztere bieten verschiedene Vorteile und sollten daher bevorzugt werden: Zum einen werden hier fachspezifische Standards und Metadatenschemata besser berücksichtigt. Spezifischere Erschließungs- und Recherchemöglichkeiten verbessern zudem die Auffindbarkeit der Daten. Werden diese in einem fachspezifischen Repositorium abgelegt, erhöht dies auch die Sichtbarkeit innerhalb der Fachcommunity. Die für Sie einschlägigen Fachrepositorien finden Sie bei den für Sie einschlägigen Konsortien der Nationalen Forschungsdateninfrastruktur.
Zu den fachübergreifenden Repositorien gehört das institutionelle Repositorium an der Philipps-Universität Marburg, data_UMR (data.uni-marburg.de). Weitere fachübergreifende Repositorien sind beispielsweise das von der EU geförderte Zenodo, Dryad oder Figshare.
Darüber hinaus können Daten auch in Datensupplementen von Fachzeitschriften veröffentlicht werden. Wenngleich diese Form der Datenpublikation zunehmend an Bedeutung gewinnt, sollten jedoch zusätzliche Archivierungsmöglichkeiten genutzt werden, um die Langzeitverfügbarkeit sicherzustellen.
Wie finde ich ein passendes Repositorium?
Wenn Sie auf der Suche nach einem passenden Repositorium sind, kann die Beantwortung folgender Fragen hilfreich sein:
-
Handelt es sich um ein fachlich passendes Repositorium?
-
Ist das Repositorium zertifiziert (z.B. CoreTrustSeal oder/und FAIR-compliant)?
-
Ist es etabliert und an spezifische Suchportale angebunden?
-
Bietet das Repositorium die gewünschten Services (z.B. Persistent Identifiers, Open Access, differenzierte Zugriffsrechte, Realisierung von Embargo-Fristen)?
-
Ist die Nachhaltigkeit des Repositorium gewährleistet?
-
Gibt es eine Exit-Strategie bzw. eine Übereinkunft zur Erhaltung der Daten bei Wegfall der Finanzierung?
-
Wie sind Datenüberlassung und Datennutzung inhaltlich und formal geregelt?
Um ein geeignetes Repositorium zu finden, können Sie die Registry of Research Data Repositories (re3data.org) nutzen. Hierbei handelt es sich um ein webbasiertes Verzeichnis, in dem Forschungsdaten-Repositorien erschlossen werden. Die Suche nach einem passenden Repositorium kann als einfache Suche durchgeführt werden. Zahlreiche Filter erlauben zudem eine Eingrenzung z. B. nach dem Fachgebiet oder Datentyp. Zur Suche gelangen Sie hier.
Was muss ich bei der Einspeisung in ein Repositorium beachten?
- Format
Zunächst ist es wichtig, dass die Daten in einem geeigneten Format vorliegen. Einige Repositorien machen hier strengere Vorgaben, andere sprechen lediglich Empfehlungen aus oder sind offen für alle Formate. Umso wichtiger ist es, diesbezügliche Überlegungen bereits im Vorfeld der Forschung anzustellen. (Wie erstelle ich einen Datenmanagementplan?) Allgemeine Hinweise und spezifische Links zu Formaten finden Sie unter: Welche Dateiformate sollten verwendet werden?
- Metadaten
Damit Daten gefunden und sinnvoll genutzt werden können, müssen sie durch Metadaten genauer dokumentiert sein. Beachten Sie hierzu bitte die detaillierten Hinweise unter: Was sind Metadaten, Metadaten-Schemata, kontrollierte Vokabulare und Dokumentationen?
- Veröffentlichung
Ein Upload in ein Repositorium bedeutet nicht automatisch eine sofortige Veröffentlichung. Unter Umständen können Gründe für eine Embargo-Frist oder eine Teilveröffentlichung sprechen. Gerade in wirtschaftsnahen Forschungsdisziplinen sind Embargos für Forschungsergebnisse üblich. Bedenken Sie deshalb, ob gewichtige Gründe gegen eine sofortige Veröffentlichung sprechen. (Spricht etwas gegen eine Veröffentlichung?)
- Bedingungen
Überlegen Sie außerdem, unter welchen Bedingungen Sie Ihre Daten veröffentlichen wollen. Hierzu existieren verschiedene Lizenzmodelle (Welche Lizenz soll ich wählen?).
Was sind Metadaten, Metadaten-Schemata, kontrollierte Vokabulare und Dokumentationen?
Metadaten sind Daten über andere Daten oder Ressourcen, in diesem Falle Forschungsdaten. Sie beschreiben die Forschungsdaten, um ihre Auffindbarkeit zu optimieren, das Verständnis der Daten für Nachnutzende zu sichern und ermöglichen bei der Nutzung gleicher, standardisierter Metadaten-Schemata auch die Verknüpfung von ähnlichen Forschungsdaten. Zu den basalsten Metadaten-Informationen gehören beispielsweise Titel, Autor oder Autorin/Primärforschende, Institution, Persistent Identifier, Ort & Zeitraum, Thema, Rechte, Dateinamen, Formate etc.
Metadaten-Schemata (häufig auch Metadaten-Standards) sind Zusammenstellungen von Kategorien zur Beschreibung von Daten. Dabei wird zwischen fachübergreifenden bzw- unabhängigen und fachspezifischen bzw. -abhängigen Standards unterschieden. Metadaten-Schemata sollen sicherstellen, dass alle Forschenden das gleiche Beschreibungsvokabular verwenden, um Interoperabilität und damit eine Vergleichbarkeit der Datensätze zu gewährleisten.
In der folgenden Tabelle sind beispielhaft einige Metadatenstandards verschiedener Disziplinen aufgeführt. Ist Ihre Wissenschaftsdisziplin nicht aufgeführt, kann meist die Auflistung des Digital Curation Centres (DCC) Aufschluss darüber geben, welche Standards für Ihren Wissenschaftsbereich in Frage kommen.
| Wissenschafts- oder Fachdisziplin | Name des/der Standards |
|---|---|
| fachübergreifende Standards | DataCite Schema, Dublin Core, MARC21, RADAR |
| Geisteswissenschaften | EAD, TEI P5, TEI Lex-0 |
| Geowissenschaften | AgMES, CSDGM, ISO 19115 |
| Klimawissenschaften | CF Conventions |
| Kunst- & Kulturwissenschaften | CDWA, MIDAS-Heritage |
| Naturwissenschaften | CIF, CSMD, Darwin Core, EML, ICAT Schema |
| Röntgenstrahlen-, Neutronen- und Myonenforschung | NeXus |
| Sozial- und Wirtschaftswissenschaften | DDI |
Vor Beginn der Dokumentation Ihrer Daten sollten Sie nach vorhandenen Metadatenschemata suchen. Dieses Vorgehen gewährleistet eine bessere Interoperabilität der zu erstellenden Forschungsdaten mit bereits erstellten Daten der gleichen Fachdisziplin und spart Ihnen die Arbeit, ein eigenes Metadaten-Schema zu entwickeln. Falls ein vorhandener Metadaten-Standard nicht die Beschreibungskategorien bietet, die für Ihre Forschung notwendig ist, lohnt es sich dennoch, einen renommierten, bereits vorhandenen fachspezifischen Standards als Basis zu nutzen und auf diesem aufzubauen, indem Sie beispielsweise zusätzliche Kategorien einarbeiten und dies den Verantwortlichen für den Standard mitteilen, damit diese das Schema erweitern können. Denn Metadaten-Standards sind lebende Gebilde, die je nach Ansprüchen der Forschenden angepasst bzw. mit neuen Kategorien angereichert werden können. Achten Sie dabei darauf, keine Änderungen an bereits vorhandenen Elementen oder Attributen vorzunehmen, um die Interoperabilität nicht zu gefährden.
Es ist möglich und meist auch notwendig, mehrere Metadaten-Schemata zu verwenden. Sie sollten wenigstens immer ein fachunabhängiges Metadaten-Schema (vorzugsweise Dublin Core) zur Beschreibung ihrer Daten verwenden, da dieses die im ersten Absatz dieses Abschnitts genannten allgemeinen Beschreibungskategorien über die erstellten Forschungsdaten abdeckt. Abb. 4 zeigt zur Veranschaulichung einen Ausschnitt für Metadaten im Dublin Core Standard. Fachspezifische Metadatenstandards hingegen erlauben die Strukturierung ihrer Daten mit Beschreibungskategorien, die auf einer stärker inhaltlichen Ebene liegen und sich von Disziplin zu Disziplin unterscheiden können.

Abb. 4: Beispiel-Metadaten im Dublin Core Standard
| Art des kontrollierten Vokabulars | Name des kontrollierten Vokabulars |
|---|---|
|
Eindeutige Identifikation von Personen, Gegenständen oder Orten |
Gemeinsame Normdatei (GND) GeoNames / International Standard Name Identifier (ISNI, ISO 27729) / |
|
allgemeine, fachübergreifende Klassifikationssysteme |
Dewey-Dezimalklassifikation (DDC) / |
| fachspezifische Klassifikationssysteme | |
| fachspezifische Vokabulare |
Agricultural Information Management Standard (AGROVOC) Standard-Thesaurus-Wirtschaft (STW) Thesaurus Sozialwissenschaften (TheSoz) |
Metadatenschemata legen also fest, welche Informationen geliefert werden sollen. Für eine bestmögliche Suche und Nutzung der Daten ist es aber außerdem wichtig, dass diese Informationen mit einem möglichst einheitlichen Vokabular wiedergegeben werden. Hierfür stehen eine Reihe disziplinspezifischer und -übergreifender kontrollierter Vokabulare in Form von Thesauri, Klassifikationen und Normdaten zur Verfügung.
Einen Überblick über verschiedene Systeme bieten z.B. das Basel Register of Thesauri, Ontologies & Classifications (BARTOC) und Taxonomy Warehouse.
Eine Dokumentation geht in der Regel über die Beschreibung der Daten via Metadaten hinaus. Sie stellt eine tiefere (fachwissenschaftliche) Erschließung dar, in deren Rahmen z.B. Entstehungskontext, Variablen, Instrumente, Methoden etc. ausführlich beschrieben werden und so die Provenienz der Daten ersichtlich wird. In vielen Fällen ist eine solche Beschreibung unerlässlich, um die Daten verstehen, prüfen und ggf. nutzen zu können.
Einführungen ins Thema Metadaten bieten z.B. der JISC Guide oder der interaktive Mantra-Kurs der Universität Edinburgh.
Was sind Persistent Identifier?
Persistent Identifier (PID) referenzieren über einen Code eindeutig auf eine digitale Ressource. Es handelt sich bei diesem Code um eine eindeutige, nicht veränderbare Benennung, mit der dauerhaft auf diese Ressource verlinkt werden kann. Durch die eindeutige Referenzierung wird der so verlinkte Inhalt zitierbar. (Wie zitiere ich Forschungsdaten?) Dabei spielt es keine Rolle, ob es sich um einen Forschungsdatensatz, Zeitschriftenartikel, Videos oder andere Ressourcen handelt. Der Persistent Identifier stellt damit sicher, dass die Ressource auch dann noch abgerufen werden kann, wenn sich beispielsweise die Internetadresse des Servers verändert. Damit spielen Persistent Identifier eine tragende Rolle bei der Aufbewahrung und Verfügbarmachung von Forschungsdaten auf lange Sicht.
Es gibt verschiedene Formen von PIDs. Eine immer gängigere Form ist der Digital Object Identifier (DOI). Eine Beispiel-DOI wäre: 10.5282/o-bib/2018H2S14-27 . Diese DOI ist weltweit nur ein einziges mal vergeben. Setzt man „https://www.doi.org/” vor die DOI, verlinkt dieser auf den Artikel von o-bib.de (s. https://www.doi.org/10.5282/o-bib/2018H2S14-27
). Neben dem DOI ist für Online-Publikationen beispielsweise auch noch die Verwendung eines Uniform Resource Name (URN) als eindeutigen Identifier gängig.
Die einschlägigen Publikationsplattformen für Forschungsdaten wie Zenodo und Figshare reservieren beim Publizieren Ihrer Daten automatisch eine DOI vor, die dieser Datensatz dann erhält. Sollten Sie in einem anderen, fachspezifischen Repositorium publizieren, sollten Sie darauf achten, dass auch dieses DOIs oder eine andere Form von PIDs anbietet. (Wie kann ich Daten veröffentlichen? / Wie finde ich ein passendes Repositorium?)
Forschungsdaten finden und nutzen
Wo finde ich Forschungsdaten?
Nicht zuletzt durch die Vorgaben und Empfehlungen von Förderern, Verlagen und Institutionen zur Zugänglichmachung von Daten stehen zunehmend Forschungsdaten für die Nachnutzung zur Verfügung. Um geeignete Forschungsdaten für den eigenen Forschungsbereich zu finden, bieten oft einschlägige Angebote aus dem eigenen Fachgebiet die erste Anlaufstelle. Dies können institutionelle oder fachliche Repositorien oder auch Datenjournale sein. Repositorien finden Sie – nach Fachgebiet aufgeschlüsselt – bei re3data.
Darüber hinaus besteht auch die Möglichkeit, Daten über generische Suchdienste zu recherchieren. Ein großer Nachteil dieser Suchdienste besteht darin, dass sie die detaillierten Metadatenschemata ihrer Quellen oft nicht adäquat abbilden können. Zudem unterscheiden sich die die jeweiligen Metadaten stark dahingehend, was sie identifizieren, also einzelne Daten, Datensets oder -Sammlungen.
Drei bekannte Suchdienste sind
Ruft Metadaten von Repositorien und Datenbanken über OAI-PMH ab. Forschungsdaten sind über die Dokumentart "Primärdaten" zu finden.
Durchsucht Metadaten aus verschiedenen Quellen wie CLARIN oder Global GBIF.
Durchsucht Metadaten von Informationsobjekten, u.a. Forschungsdaten (Objekttyp ‚Dataset'), die bei DataCite mit DOIs registriert sind. Die Metadaten werden z.T. auch von den anderen beiden Diensten abgefragt.
Für die Nachnutzung selbst sind die jeweiligen Rechte (Lizenzen, ggf. Nutzungsverträge) bindend. Sie können u.a. festlegen, wer die Daten zu welchem Zweck und für welche Zeit nutzen darf.
Wollen oder können Sie nicht auf bereits vorhandene Forschungsdaten zurückgreifen, können Sie natürlich geeignete Forschungsmethoden ihrer Fachdisziplin zur Datengewinnung anwenden. Die Coffee Lecture von Dr. Samuel de Haas und Jan Thomas Schäfer auf dem YouTube-Kanal der UB der JLU Gießen bietet beispielsweise Informationen zur Datengewinnung über Web Scraping und Text Mining und dem Umgang mit Big Data in der Praxis.
Wie zitiere ich Forschungsdaten?
Um die Nutzung und Nachnutzung von eigenen und fremden Forschungsdaten im Sinne der guten wissenschaftlichen Praxis adäquat zu dokumentieren, ist eine korrekte Datenzitation unerlässlich.
Im Falle von Fremddaten wird hierdurch außerdem die wissenschaftliche Leistung ihrer ‚Urheber' gewürdigt. Wie bei der Zitation von anderen Publikationen können die Konventionen zur Zitation von Daten formal abweichen. Inhaltlich verbindet sie jedoch der Anspruch einer eindeutigen Identifizierbarkeit der Datenquelle. Die FORCE11 Data Citation Synthesis Group hat Empfehlungen zur Datenzitation erarbeitet. Ihnen zufolge umfasst eine vollständige Datenzitation:
Autor(en), Jahr, Titel der Forschungsdaten, Datenrepositorium oder Archiv, Version, weltweit Persistenter Identifikator
Weitere optionale Angaben, die im Rahmen einer Zitation sinnvoll sein können, sind Edition, URI, Resource Type, Publisher, Unique Numeric Fingerprint (UNF) und Location (vgl. Alex Ball & Monica Duke 2015).